6.1. Принцип организации нечетких систем управления.
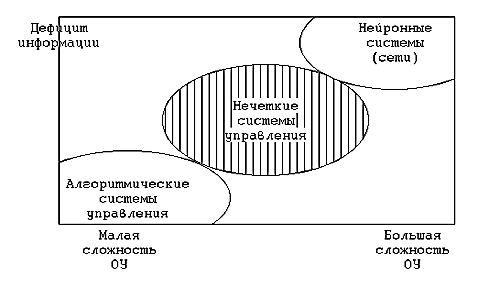
В настоящее время начинают находить широкое применение так называемые нечеткие системы управления (fuzzy-системы), основанные на нечеткой логике, разработанной профессором Лотфи Заде еще в 1965 году [7]. Особенно эффективно применение нечетких систем управления там, где объект управления достаточно сложен для его точного описания и существует дефицит априорной информации о поведении системы. Область применения нечетких систем управления показана на рис. 6.1.
Принцип действия нечетких систем управления
основан на выполнении нечеткого логического вывода типа ![]() Нечеткие системы имеют базу знаний и зачатки искусственного интеллекта.
Нечеткие системы имеют базу знаний и зачатки искусственного интеллекта.
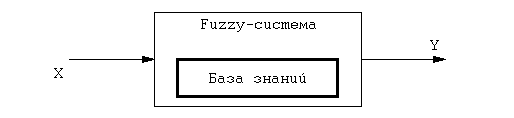
Простейшая система управления, функциональная схема которой показана на рис. 6.2., реализует один восходящий нечеткий вывод, схему которого можно представить в следующем виде
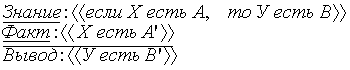

При дискретном представлении функции принадлежности А можно рассматривать как вектор
Аналогично
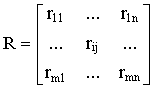 (6.1)
(6.1)Заде следующим образом определил результат нечеткого восходящего вывода для В’
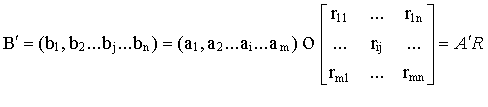 (6.2)
(6.2)Из (6.2) вытекает, что
где ![]() - логическое умножение (MIN);
- логическое умножение (MIN);
![]() - логическое
сложение (MAX).
- логическое
сложение (MAX).
Для непрерывной логики логическое умножение эквивалентно нахождению минимального значения, а логическое сложение - максимального.
Мамдани предложил следующий вариант нечеткого отношения, наиболее часто используемый на практике
где З- логическое умножение (MIN).
Рассмотрим реализацию нечеткого управления
в простейшей системе управления с одним входом и одним нечетким выводом
типа ![]() на примере системы управления компенсационной емкостью, функциональная
схема которой показана на рис. 6.4.
на примере системы управления компенсационной емкостью, функциональная
схема которой показана на рис. 6.4.

Система должна следить за тем, чтобы в
компенсационной емкости К.Е. было достаточное количество жидкости, но не
было переполнения.
Система реализует нечеткий вывод типа:
“Если уровень “высокий”, то открыть” клапан К”.
Таким образом входной лингвистической
переменной в данном случае является переменная:
А = “Высокий”,
а выходной
В = “Открыть”.
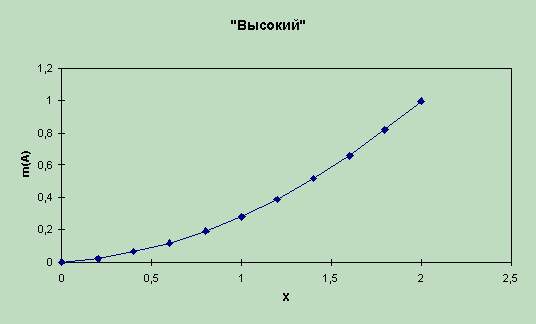
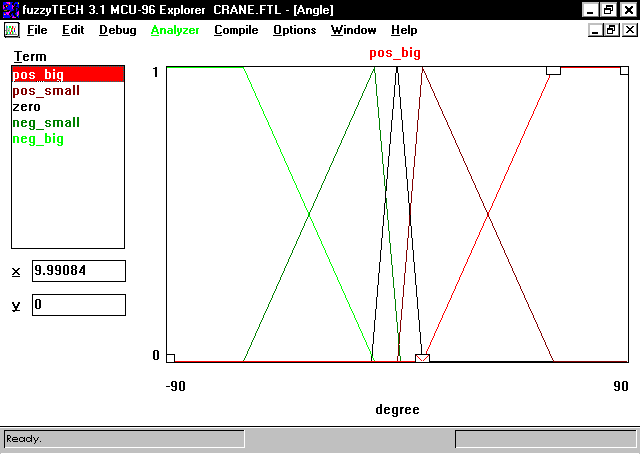
Функции принадлежности, связывающие физическую
входную переменную “Уровень” в метрах с лингвистической переменной “Высокий”
и выходную переменную “Угол поворота вентиля” с лингвистической переменной
“Открыт” показаны соответственно на рис. 6.5, а) и б).

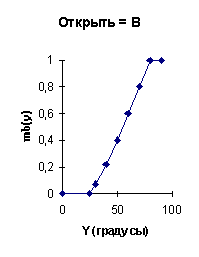
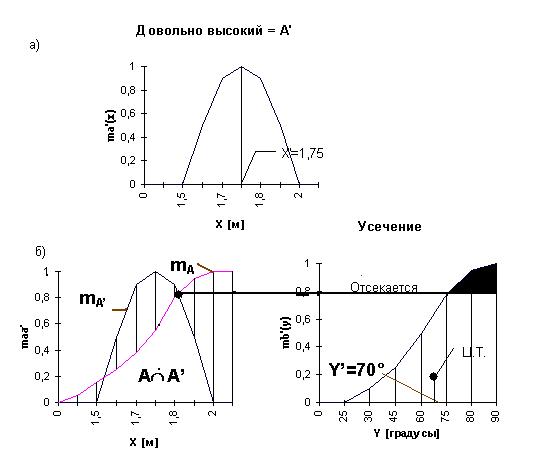
6.2. Реализация нечеткого управления.
Нечеткое управление может быть реализовано
специальными нечеткими контроллерами, в основе которых лежит так называемая
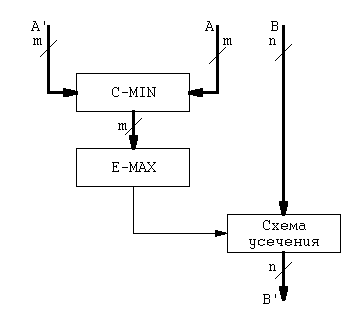
машина нечетких выводов, структура которой показана на рис. 6.7.[8].
Эта машина реализует нечеткий вывод типа
“Если А, то В” по формуле (6.5), как показано на рис. 6.6. Блок, реализующий
функцию C-MIN, осуществляет пересечение
множеств А и А’. Блок, реализующий
функцию E-MAX, выделяет из множества
А? А’
элемент с максимальным значением, который осуществляет усечение множества
В, превращая его во множество В’
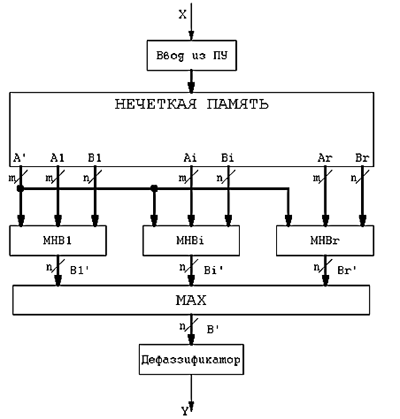
. Базовая архитектура нечеткого контроллера,
выполняющего много нечетких выводов (r),
содержит r машин нечетких выводов (МНВ),
как показано на рис. 6.8. Кроме МНВi базовый
нечеткий контроллер содержит нечеткую память в которой хранится база знаний
и схема объединения результатов выводов - MAX
с дефаззификатором.
Нечеткое управление может быть реализовано с помощью обычных или специализированных логико-арифметических контроллеров, в которых нечеткие выводы выполняются путем вычисления характеристических значений выходной лингвистической переменной через характеристические значения входных лингвистических переменных по логическим формулам использующим логические операции “И” и “ИЛИ”.
Переход от лингвистических переменных,
принимающих различные лингвистические значения - ТЕРМЫ, производится через
соответствующие характеристические функции - функции принадлежности,
показанные на рис. 6.9. Считается, что для реализации простейших алгоритмов
нечеткого управления достаточно, чтобы каждая лингвистическая переменная
содержала от 3 до 7 термов.
Z-функция
p -функция
l -функция
S-функция

Разработка алгоритма нечеткого управления традиционно содержит три этапа:
Этап 1. Фаззификация
- переход от физических переменных к лингвистическим переменным и их
характеристическим функциям. Фаззификация может быть осуществлена путем
выполнения следующих шагов:
Шаг 1. Для каждого терма взятой лингвистической переменной находится
числовое значение физической величины (или диапазон значений), наилучшим
образом характеризующей данный терм и этим значениям присваивается характеристическое
значение равное “1”.
Шаг 2. Для каждого терма выбирается диапазон значений физической
переменной при которых характеристическая функция принимает значение “0”.
Шаг 3. После определения
экстремальных значений определяются промежуточные значения характеристических
функций путем выбора типовых функций, показанных на рис. 6.9.
Этап 2. Построение
нечетких правил.
Большинство нечетких систем используют продукционные правила для описания
зависимостей между лингвистическими переменными. Типичное продукционное
правило состоит из антецедента (часть ЕСЛИ...) и консеквента (часть ТО...).
Антецедент может содержать более одной посылки. В этом случае они объединяются
посредством логических связок “И” или “ИЛИ” т.е. операндов MIN/MAX.
Сам процесс вычисления нечеткого
правила носит название нечеткого логического вывода и подразделяется на
два этапа: обобщение и заключение.
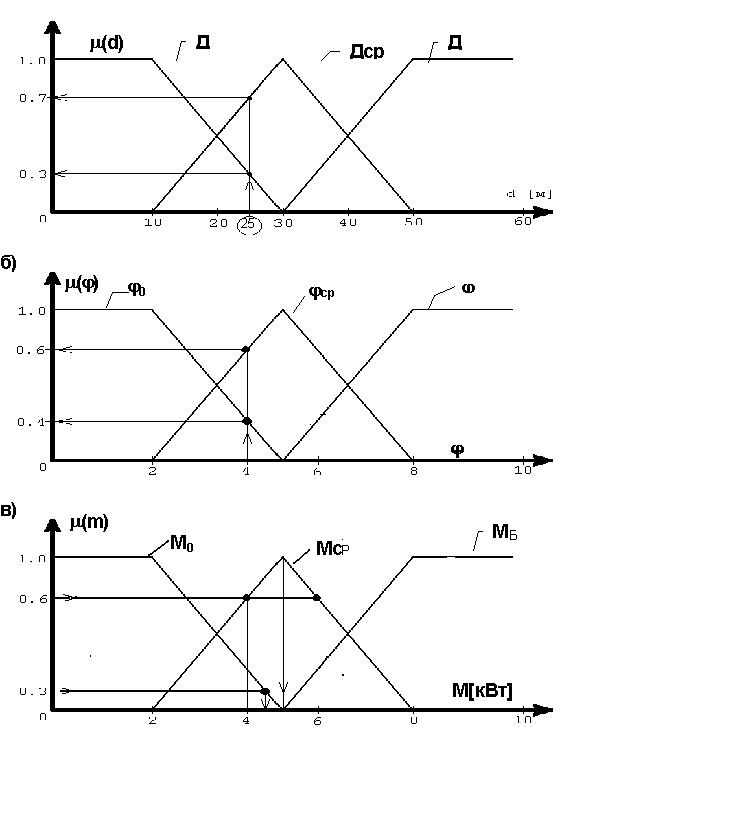
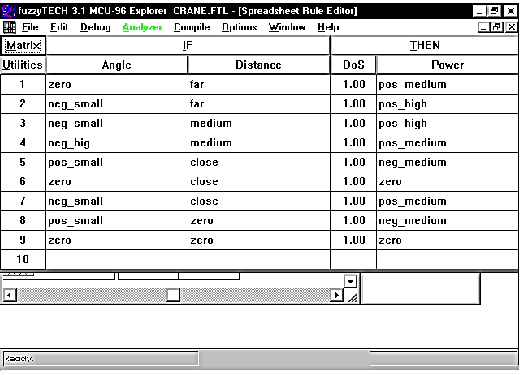
Например, для системы управления башенным
краном, функциональная схема которой показана на рис. 6.10, входными переменными
являются расстояние (дистанция) от каретки до стены d[м],
и угол отклонения груза от вертикали j
° , а выходной
переменной - мощность, подаваемая на
двигатель каретки m. Допустим, что
каждая из этих переменных имеет три терма - нулевое, среднее и большое,
которым соответствуют свои характеристические величины:

Этап 1. Фаззификация.
На этом этапе разрабатываются функции принадлежности для всех трех
переменных, показанные на рис. 6.11.
Этап 2. Построение
продукционных правил.
Перечислим все возможные комбинации входных переменных
Разобьем их на три группы, соответствующие трем термам выходной переменной,
например, так, как показано выше.
На основании этого разбиения можем написать формулы, соответствующие
продукционым правилам вычисления выходных переменных
Произведем вычисления для конкретных значений
d=25м и j
=4° ,
см. табл. 6.1.
Результаты вычисления по формулам (6.6)
| j 0 | j ср | j б | D0 | Dср | Dб | М0 | Мср | Мб |
| 0.4 | 0.6 | 0 | 0.3 | 0.7 | 0 | 0.3 | 0.6 | 0 |
Этап 3. Дефаззификация.
Принцип дефаззификации показан на рис. 6.11.в),:
-по методу CoM получим m=4.5 квт;
-по методам MoM и
CoA m=5 квт.
Таким образом, при принятых значениях
входных переменных d и j
надо подавать на двигатель среднюю мощность,
так как величина степени принадлежности этого терма преобладает над другими.
а)
После бурного старта прикладных нечетких
систем в Японии, многие разработчики в США и Европе обратили внимание на
новую технологию. Но к этому моменту время было упущено и мировым лидером
в области нечетких систем стала Япония. К концу 80-х годов в этой стране
был налажен выпуск специализированных нечетких контроллеров выполненных
по технологии СБИС. Догонять японцев значило потерять массу времени. Поэтому
фирмой Intel было принято альтернативное
решение. Имея большое количество разнообразных контроллеров от MCS-51
до MCS-96, которые на протяжении многих
лет успешно используются во многих приложениях, Intel решила
предоставить разработчикам средство разработки приложений на базе этих
контроллеров, но с использованием технологии нечеткости. Создание подобной
системы позволило избежать значительных затрат на создание собственных
нечетких контроллеров, а разработанная система, получившая название fuzzyTECH,
завоевала огромную популярность не только в США и Европе, но и в Японии.
Сейчас существует много версий fuzzyTECH.
Все они различаются как по своим возможностям, так и по своей цене. Самый
простой из семейства fuzzyTECH - это
пакет fuzzyTECH Explorer Edition. Explorer -
это великолепное средство обучения. Он предоставляет пользователю большие
возможности по практическому освоению нечеткой технологии. Существует и
более мощный профессиональный пакет fuzzyTECH MCU-96,
ориентированный на микроконтроллеры Intel семейства
MCS-96. Еще один вариант - это fuzzyTECH
On-line Edition. Этот пакет позволяет отлаживать
готовую систему, отлавливая ошибки прямо “на
лету”. В приложениях, работающих в
реальном масштабе времени, это незаменимое средство отладки. Профессиональные
редакции fuzzyTECH поддерживают многие
из последних достижений нечеткой технологии: арбитражные функции принадлежности,
современные методы дефаззификации и многое другое.
FuzzyTECH - это полностью графическое
средство поддержки разработки приложений на основе нечеткой логики. Это
средство моделирования и оптимизации всего проекта. Обладает совместимостью
с обычными средствами разработки. Графическое представление на экране всех
стадий разработки позволяет найти множество путей оптимизации проекта.
Наконец, это генератор кода, который поддерживает большинство современного
оборудования, при этом разрабатываемый код может быть сгенерирован как
код языка C. Ассемблерный код весьма
функционален, точно соответствует возможностям применяемого аппаратного
обеспечения и типу микроконтроллера.
Обычно выделяется пять стадий разработки
проекта с помощью fuzzyTECH:
LV-окне. LV-окно всегда открыто и может
быть свернуто до пиктограммы, но не закрыто. LV-окно содержит все лингвистические
переменные текущего проекта по именам в алфавитном порядке. Если нужно
всегда указывать переменные в другом порядке, продолжите все имена переменных
буквами, например 'AA_FirstVar', 'AB_SecVar'.
В нечеткой логике, различные величины
для данной лингвистической переменной представляют собой понятия, а не
числа. В нечеткой логике, даже приближенные описания такие как “чрезвычайно
близко” и “очень далеко” возможны, поскольку каждый лингвистический терм
представлен специфическим нечетким множеством, названным Функцией Членства.
Конечно, техническая величина измерима
как точная. Степень с которой точная величина принадлежит ко множеству
представлена числом, лежащим между 0 и 1. Эта величина названа Степень
Членства (или степень принадлежности) (Membership Function - MBF). 0 означает,
что переменная определенно не принадлежит ко множеству; 1 отражает абсолютное
членство. Величины между 0 и 1 представляют частичное членство, таким образом
учитываясь в выражениях, которые частично истинны и частично ложны (задание,
которое невозможно выполнить используя стандартную логику). В нечеткой
логике, Степень Членства обычно нормирована в интервале [0; 1]. Технические
цифры представлены на горизонтальной оси функции, а степени членства на
вертикальной. Технические цифры названы базовой переменной. Хотя научные
публикации предложили много разных типов функций членства для нечеткой
логики, в большинстве практических приложений используются Стандартные
Функции Членства. Стандартные Функции Членства могут быть в общем представлены
L-формой определения. Научные исследования предлагают несколько иной подход
к этой задаче. Он базируется на психо-лингвистическом исследовании человеческой
классификации длительных переменных, получающим S-форму функции членства.
Пока большинство приложений использует стандартные MBF через S-тип MBF,
хотя некоторые методы вывода функций членства и некоторая техника адаптации
требует более общих функций. Для удобства проектирования этих типов функций
членства и для наиболее эффективного динамического кодового представления,
функции произвольного членства наилучшим образом приближенно представимы
как линейные многоугольники. Стандартные функции членства - Z, Лямбда,
Pi и S-типы (рис. 6.9). Все эти типы стандартных функций математически
могут быть представлены как часть функций - линейных многоугольников с
вплоть до 4 определяющих точек. FuzzyTECH позволяет определять ассиметричный
характер параметра "форма". Имейте в виду, что S-типа функции членства
требуют больше динамического кода и больше вычислительного времени, если
они не сохранены как таблицы.
Фаззификация означает оценку всех степеней
членства в точке специфической операции. Результат фаззификации используется
в качестве входа для Нечетких Правил. Если переменная используется в качестве
выходной в нечеткой системе, лингвистические термы могут быть вновь переведены
в точные физические величины. Эти вычисления названы дефаззификацией.
В большинстве приложений, количестве используемых
термов - между 3 и 7. Менее чем 3 используемых терма - редкое явление вследствие
того, что, когда люди оценивают реальные числа, те которые имитируют лингвистические
переменные, они обычно имеют по крайней мере три величины в уме - два предела
и середина. Количество используемых термов редко превышает 7 поскольку
оценка чисел включает краткосрочную память, которая лучше всего работает
с не более чем 7 символическими величинами. Переменные с “центром” или
“нулем” наилучше работают с нечетным количеством термов (рис. 6.13).
Есть в основном два разных метода для
определения подходящего количества термов для данной проблемы. Для разработчиков
с некоторым опытом в создании нечетких систем, один метод - сформулировать
примерные правила даже перед проектированием функций членства. Это
учитывается при быстрой оценке - сколько
термов должны использо-ваться?
Для пользователей без предшествующего опыта
в разработке нечетких систем или если примерные правила легко не формулируются,
наилучший метод - во-первых, создать три терма (два предела и середина).
Если большее термов нужно создать в течении разработки, то они могут легко
быть добавлены при использовании fuzzyTECH.
Большинство нечетко-основанных систем
используют продукционные правила, чтобы представить отношения между лингвистическими
переменными и получить данные от входов. Продукционные правила состоят
из условия (ЕСЛИ-часть) и вывода (ЗАТЕМ-часть). ЕСЛИ-часть может состоять
из более чем одного предусловия, компонуемых вместе лингвистическими конъюнкциями
(И и ИЛИ) (рис. 6.14).
Используя стандартные MAX-MIN/MAX-PROD
методы, оптимизация базового правила часто состоит из произвольного дополнения/удаления
правила. Этот метод может дать результат по методу проб и ошибок так как
индивидуальное значение правила может быть выражено только как 0 или 1.
По этой причине, большинство редакций fuzzyTECH поддерживают усовершенствованную
стратегию вывода - Нечеткие Ассоциативные Карты (FAM). С FAM, каждое правило
наделено Степенью Поддержки (DoS), представляющей индивидуальное значение
правила. Таким образом правила сами могут быть "нечетки" - знача, с достоверностью
между 0 и 1. Если работа с нечеткими технологиями только начинается, то
используйте правила со степенью поддержки только 0 и 1.
Достоверность вывода вычисляется компоновкой
достоверности условия в целом со степенью поддержки оператором композиции.
Когда продукционный оператор используется в качестве оператора композиции,
степень поддержки отражает “значение” правила.
Результат, полученный из оценки нечетких
правил - нечеткий. Функции Членства используются, чтобы вновь перевести
нечеткий вывод в точную величину. Этот перевод известен как дефаззификация
и может быть выполнен с использованием различных методов.
Дефаззификация, используемая редакциями
fuzzyTECH: